- 2005-11-21 (月)
- Perl


仕事で Benchmark モジュールを使う機会があったので、使い方&結果情報の読み取り方をまとめてみました。基本的には perldoc 読めばオールオッケーでしょ?と思っていたのですが、docs では結果情報の読み方についてはあんまり触れられていなかった為、ガッツリ補足してみました。
基本
とある2種類のコードの実行速度を比較計測するには以下のようなソースを記述します:
bench.pl
#!/usr/bin/perl
use strict;
use warnings;
use Benchmark qw(timethese cmpthese);
sub hogeLoop1 {
my $str;
for my $i (1 .. 10000){ $str .= $i }
}
sub hogeLoop2 {
my $str;
for my $i (1 .. 20000){ $str .= $i }
}
timethese(500,{
PatternFast => 'hogeLoop1',
PatternSlow => 'hogeLoop2',
});
で、この pl ファイルに実行権限つけた上でshellにて実行すると以下の様な結果が出力されます:
$ ./bench.pl
Benchmark: timing 500 iterations of PatternFast, PatternSlow...
PatternFast: 3 wallclock secs ( 3.58 usr + 0.00 sys = 3.58 CPU) @ 139.66/s (n=500)
PatternSlow: 8 wallclock secs ( 7.34 usr + 0.00 sys = 7.34 CPU) @ 68.12/s (n=500)
計測対象とした PatternFast と PatternSlow それぞれに対してなにやら文字列が出力されていますが、これらの情報の意味は下記の通りです:
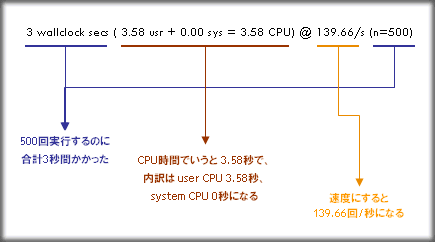
wallclock secs は訳すと「壁時計でいう秒数」、つまり我々現実世界での秒数の事を意味しています。よってこの例の結果としては、
PatternFast は PatternSlow の2倍以上高速である
事が読み取れるかと思います。なお、user CPU時間・system CPU時間とは何ぞや?と思いWEBを探してみたところ、例えば Linux World Online の「コマンドの実行時間を表示する」なる記事文中から引用すると
ユーザーCPU時間(user)とは、実行したコマンドの処理にCPUを使用した時間のこと。一方、システムCPU時間(sys)とは、当該コマンドの実行時にOSの機能(例えばメモリ/CPU間のデータ入出力など)がCPUを使用した時間のこと。
という事になるようです。
見やすい比較結果 - cmpthese
基本で紹介したソースコード中の、timethese 関数をコールしている部分を下記のようにちょろっと修正する事で、より人間が理解しやすい比較表を追加で出力してくれます > cmpthese 関数:
my $result = timethese(500,{
PatternFast => 'hogeLoop1',
PatternSlow => 'hogeLoop2',
});
cmpthese($result);
追加出力結果:
Rate PatternSlow PatternFast
PatternSlow 68.1/s -- -51%
PatternFast 140/s 105% --
一番上の行がもっとも遅いコード、一番下の行がもっとも速いコード、という順番で出力されます。Rate はさっきと同じく速度 n回/秒 の事です。列情報は、自分以外のコードとの速度比率をあらわしていて、この場合、PatternFast は PatternSlow の+105%、つまり2.05倍高速でしたよ、という事を示しています。
子プロセスを含んだコードの計測結果
計測対象のコード中に、なんらかの子プロセス実行コード(qx, system, `` 等)が含まれていると、Benchmark の出力結果が若干変化します。
bench4.pl
#!/usr/bin/perl
use strict;
use warnings;
use Benchmark qw(timethese cmpthese);
sub hogeLoop1 {
my $str;
for my $i (1 .. 10000){
$str .= $i;
qx(date) if(!($i%1000));
}
}
timethese(100,{
withChildProc => 'hogeLoop1',
});
出力結果:
$ ./bench4.pl
Benchmark: timing 100 iterations of withChildProc...
withChildProc: 4 wallclock secs ( 1.39 usr 0.34 sys + 1.18 cusr 0.90 csys = 3.81 CPU) @ 57.80/s (n=100)
CPU時間の箇所が (usr + sys = CPU) という表記から (usr sys + cusr csys = CPU) に変化しています。これは
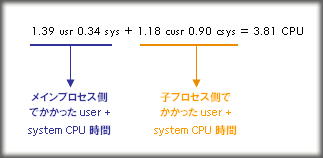
のように、実行コードのプロセスと、中でコールされる子プロセス分のCPU時間が別々に計測されている事を示しています。※ cusr とは child user CPU、csys とは child system CPU の意味。
子プロセスを含んだコードの計測結果 - 重要なポイント
先ほどの計測結果の、速度 n回/秒の部分を見てみると 57.80回/秒 となっていますが、良く考えてみると
- コードを100回実行してみた
- 計測結果から wallclock secs は4秒だった
- → 100÷4 = 25回/秒 って計算になる
なんですが、計測は何故か 57.80回/秒 と、ほぼ倍の数値になっています。おかしいっすよね。何故こうなるかと言うと、子プロセスを含んだコードの計測の場合、wallclock secs は子プロセスも含んだ全体の処理時間を表すものの、
速度 n 回/秒に関しては子プロセスの処理時間を除いた、メインプロセス側の時間のみを計算対象としている
からだと思われます。何故そうなっているかまでは知識不足ゆえ判りませんでしたが(汗
実証サンプルとして、最初の「基本」のセクションで取り上げた2つの関数 hogeLoop1 と hogeLoop2 をそれぞれ別々の *.pl 実行ファイルとして切り出した上で、これらを子プロセスとしてコールする計測コードを用意してみます:
hogeLoop1.pl
#!/usr/bin/perl
my $str;
for my $i (1 .. 10000){ $str .= $i }
hogeLoop2.pl
#!/usr/bin/perl
my $str;
for my $i (1 .. 20000){ $str .= $i }
childProcBench.pl
#!/usr/bin/perl
use strict;
use warnings;
use Benchmark qw(timethese cmpthese);
timethese(500,{
PatternFast => 'qx(./hogeLoop1.pl)',
PatternSlow => 'qx(./hogeLoop2.pl)',
});
hogeLoop1,2 とも処理内容は基本セクションの時とまったく同じです。基本セクションでの計測結果(=すべて1つのプロセス内で完結する場合の計測結果)は
- hogeLoop1 : 139.66/s
- hogeLoop2 : 68.12/s
でした。では子プロセスとしてコールする形に変えた場合はどうなるかというと、
$ ./childProcBench.pl
Benchmark: timing 500 iterations of PatternFast, PatternSlow...
PatternFast: 7 wallclock secs ( 0.02 usr 0.15 sys + 5.95 cusr 0.86 csys = 6.98 CPU) @ 2941.18/s (n=500)
PatternSlow: 12 wallclock secs ( 0.05 usr 0.13 sys + 10.81 cusr 0.77 csys = 11.76 CPU) @ 2777.78/s (n=500)
結果、
- hogeLoop1 : 2941.18/s
- hogeLoop2 : 2777.78/s
と、別の pl ファイルにコードを移しただけなのに速度数値は200-300倍位速くなってます。でも wallclock secs の方は7秒と12秒・・・基本セクションの時より、双方とも若干遅くなっていますよね。子プロセスを起動する分のコストと考えれば wallclock secs の増加は納得できるので、やはり、いきなり300倍も速くなったかのような速度計測結果の方がおかしいかと。これは前述したとおり、
速度 n 回/秒に関しては子プロセスの処理時間を除いた、メインプロセス側の時間のみを計算対象としている
からだと考えると納得行くかと思います。
終わりに
というわけで、子プロセス実行を含むコードを Benchmark する時は以上の点を押さえて、評価を間違えないようにしましょう。僕はこれに気付くまで、さんざん無駄に一喜一憂しちゃってました(涙
※なんかおかしなこと言ってたら是非ツッコミ入れてください。嘘っぱち情報晒したままは恥ずかしいので...
- Newer: XML::Simple は遅い説における意外な落とし穴
- Older: 同一カテゴリー内の前後の記事へのリンクを張る